分布式系统
- 分布式系统的迭代过程(单体应用-分布式应用)
- 分布式系统的特点: 分布性、对等性、自治性、并发性;
- 分布式系统的挑战: 由于已经有非常成熟的解决方案,这些成熟的方案已经帮我们屏蔽掉底层所遇到的核心问题,因此我们只需要解决应用层面上的问题即可。事实上,我们只需要解决我们自己项目应用层面的问题和使用这些已有成熟方案的使用上的问题即可。
- 两个讨论的方向:
- 一个是应用层面考虑(功能适用性和经济适用性)
- 功能适用性: 回答能不能满足需求的问题。
- 性能需求: 三高(高可用、高性能、高并发)、可扩展、易维护;相关衡量指标:QPS、TPS、SLA、资源使用情况(IO、CPU、内存、磁盘)、可监控、可观测、可追踪;
- 功能需求:缓存、事务、ID、锁……
- 经济适用性: 回答花多少钱的问题;人力成本(人+时间)、资源成本;
- 功能适用性: 回答能不能满足需求的问题。
- 一个是底层核心层面(NPC);
- 本质上讲是 NPC,具体表现(网络延迟、消息丢失与无序、三态、);实际上由于我们多是应用层,所以我们要考虑的是 1. 解决应用层所遇到的问题(网络三态、延迟、消息丢失与无序、脑裂问题);2. 了解中间件系统的解决方案;
- 一个是应用层面考虑(功能适用性和经济适用性)
- 本质上讲是 NPC,具体表现(网络延迟、消息丢失与无序、三态、);实际上由于我们多是应用层,所以我们要考虑的是应用层所遇到的问题(网络三态、延迟、消息丢失与无序、)
- 两个讨论的方向:
- 分布式系统基本性能需求和相关指标
- 性能需求: 三高(高可用、高性能、高并发)、可扩展、易维护;
- 相关指标:QPS、TPS、SLA、资源使用情况(IO、CPU、内存、磁盘)、可扩展性、可维护性;
- 分布式系统基础理论:
- CAP
- 三特性的解决方案
- 一致性:XA 方案、Paxos 算法、ZAB 算法、Raft 算法、一致性 Hash 算法
- 可用性:评判标准、心跳检测、异地多活和同城双活、gossip、隔离、限流、负载均衡
- 分区容错:日志复制、主备、互备、集群
- 三特性的解决方案
- BASE
- CAP
- 分布式系统应解决的问题:
- 应用层面(锁、缓存、事务、 消息、 ID、Job、会话)
- 治理层面(负载均衡、限流、注册与发现、RPC、监控和报警、链路追踪)
分布式ZK相关内容,数据存储、应用场景、与 kafka 的关系、相关面试题- 分布式系统的问题
- 基本理论(CAP、Base)
- 一致性 C,XA 方案、Paxos 算法、ZAB 算法、Raft 算法、一致性 Hash 算法
- 可用性 A,评判标准、心跳检测、异地多活和同城双活、gossip、隔离、限流、负载均衡
- 容错性 P,日志复制、主备、互备、集群
- CP 与 AP 权衡问题,WARO 机制、Quorum 机制
- 分布式缓存
- 分布式事务(背景、实现方式、优缺点分析、具体实现【seata 原理】)
- 分布式锁(产生背景、实现方式、优缺点分析)
- 分布式 ID
- 分布式消息
- 分布式调度
- 分布式服务
- 分布式搜索
- 分布式会话: 发展历程、各自过程中遇到的问题及解决方案、分布式会话实现方案
- 高可用的理解
- 高并发的理解
- 分库分表
- 集群:
- 负载均衡
- 一致性 Hash 等
两大块:
- 我们自己写的代码,应该怎么实现我们的需求:应用层面(锁、缓存、事务、 消息、 ID、Job、会话)
- 我们用的中间件是怎么实现我们的需求的:治理层面(负载均衡、限流与熔断、注册与发现、RPC、监控和报警、链路追踪)
- [基础理论]
- 分布式锁 lock.md
- [分布式事务]
- [分布式 ID]
- [分布式缓存]
- [分布式消息]
- [分布式存储(分库分表)]
- [布式会话]
- [分布式 Job]
10. 参考
- 24.分布式系统的困境与 NPC 性别研究
- 《数据密集型应用系统设计》第八章《分布式系统的挑战》笔记 - codedump 的网络日志
- 分布式系统的 4 种典型问题
- 分布式系统的 5 大特征
- 分布式系统遇到的十个问题-分布式系统的定义
- 24.分布式系统的困境与 NPC 性别研究
来自: 分布式系统遇到的十个问题
应用场景
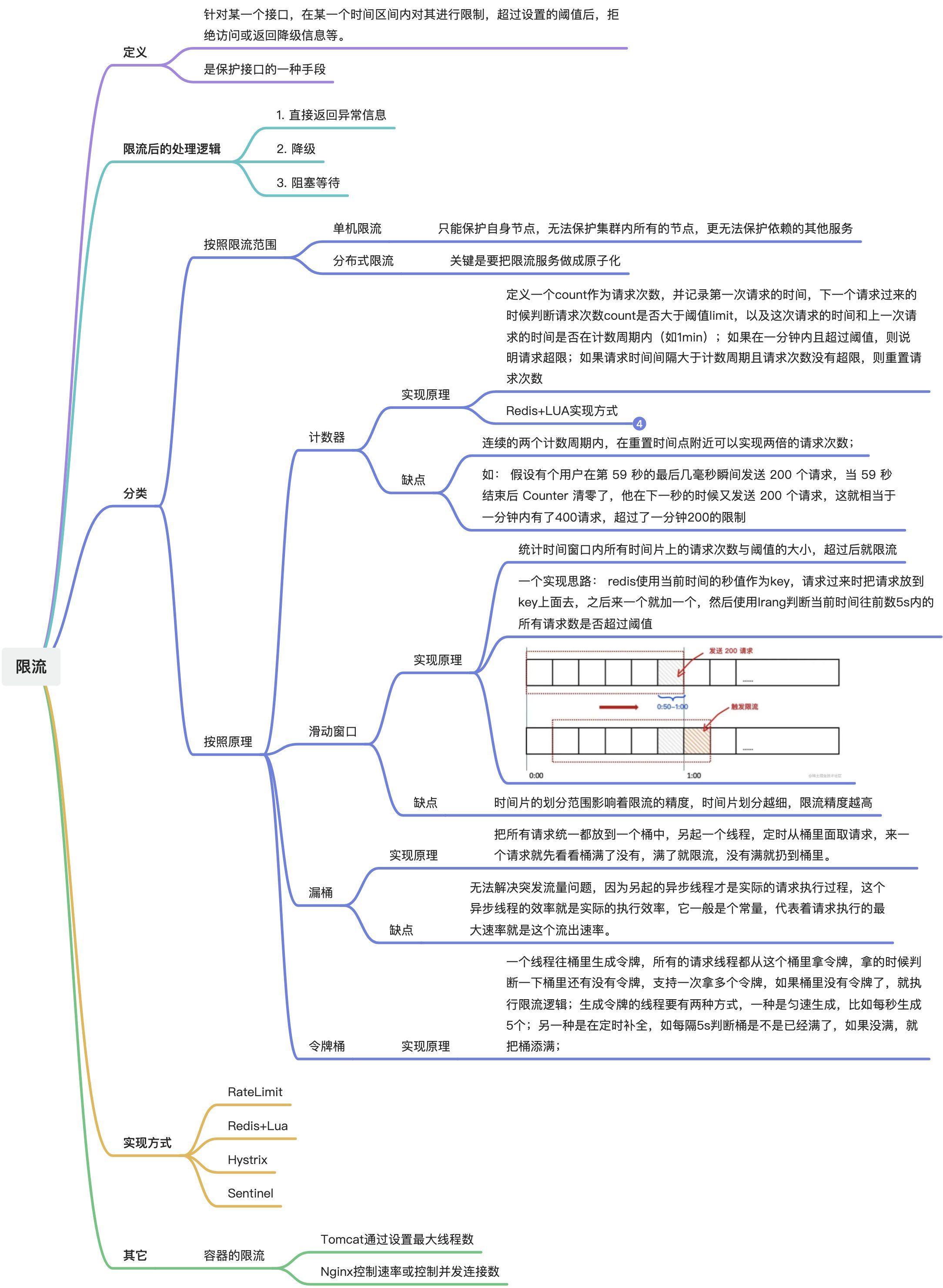
统计中心防止用户过多刷新造成系统压力
实现过程
其他方案 sential 实现过程 gateway 限流方案
系统高可用设计研究
高可用背景
- 组件多而杂
- 影响因素多而杂
可用性分析方法
可用性分析模型
单个组件
多个组件构成单个系统 串行 并行
衡量标准
服务等级协议( SLA, Service Level Agreement),一般用 n 个 9 来表示。
总结
- 我们说系统高可用是指多个组件构成整个系统的情况;
- 评判系统高可用的方法:
- 判断系统的部署模型;
- 根据部署模型计算;
高可用的常用手段
高可用系统设计
我们一直在谈系统要支持高可用,但是很多人都不知道什么是高可用、哪些原因会造成系统不可用,更不要说有哪些手段可以使系统变的高可用。 我们今天来聊一聊这个话题。
系统不可用的背景
在计算机发展前期,我们只能使用单机软件,这些单机软件只服务于使用个人计算机的用户,用户想要使用服务,就要去官网下载对应的软件,然后安装到个人计算机上,这就是最原始的计算机软件的使用方式,也是最原始的 CS 模式(Client/Server)的软件使用方式,可这种方式会造成一些问题,比如说针对个人应用的软件,当软件系统推送应用升级的消息给用户时,就会有人选择不升级,这就造成了某些业务无法覆盖到全体用户,软件制造商也就需要同时维护不同版本的软件,这会造成企业研发成本的严重浪费;再比如说,针对企业提供服务的软件,软件制造商还需要额外提供人力去企业现场提供升级维护服务,这也会产生了巨大的人力成本。但是,随着计算机网络的发展,针对这些问题,人们提出了一种新的软件服务方式,也就是现在大家经常使用到的 BS(Browser/Server)模式的软件服务形式,这种服务模式通俗点讲,就是统一提供一个 web 网站,所有的用户都使用同一个网站,这样软件制造商就可以只维护一套代码,升级维护问题也迎刃而解。但 BS 模式运行一段时间后,人们发现用户越来越多,用户产生的数据也越来越多,经常会出现系统不可用的现象,于是人们开始针对这个问题进行研究。
系统不可用的原因分析
研究系统不可用现象时,可以从系统的部署模型去探讨。系统的部署模型无非就四部分内容,用户、硬件、软件和连接设备。下面我们分别从这几个方面讨论一下造成系统不可用的原因。在软件方面,比如有些代码写的不够健壮,系统运行一段时间后代码问题暴露出来,这会造成系统不可用;应用系统的某个节点### 包括应用系统某个模块和应用系统所使用的中间件突然出现问题,不再对外提供服务也会造成系统不可用;在连接设备方面,计算机网络抖动造成服务不够稳定,时而提供服务时而不提供服务,也会造成系统不可用;在硬件方面,计算机硬件设备出现故障,导致整个服务器宕机,也会造成系统不可用;在用户方面,会出现网络黑客攻击、用户量激增、自然灾害造成机房损毁、人为破坏服务器等也会造成系统不可用。
系统可用性的评判标准
BS 模式发展过程中并不是立刻就有理论支撑的,人们为了快速占领市场先机,都是先把项目上马,然后人们遇到一个问题就解决一个问题,后来人们说没有理论不行呀,于是人们就提出系统可用性的评判标准。所谓系统可用性的评判标准就是,一个系统正常运行的时间占全年时间的百分比,如百分之九十九点九九九,也就是五个“九”的标准,代表着全年中有百分之九十九点九九九的时间,系统是正常运行的时间,一年按照 365 天来算,也就是大概会有半分钟的不可用时间。现在互联网大厂中的系统可用时间大多在五个“九”、六个“九”的标准,并且这些指标都与程序员的绩效考核挂钩。总之,系统可用性的评判标准就是系统全年可用时间的百分比。知道了系统可用性的评判标准后,现在我们需要从另外一个角度分析出软件过程中所有可能会造成系统不可用原因,然后针对这些原因逐一解决。
如何保证系统可用性
我们假设系统硬件和系统网络可用性为百分之百,这样我们就可以只需要保证用户侧和软件侧的可用性,就可以满足系统高可用的目标。实际上,系统硬件和系统网络出现问题的概率本身就很低,几乎可以忽略不计,而用户侧造成系统不可用的原因,可以通过解决其他三方面的问题来解决。因此保证系统高可用就变成了如何保证软件系统高可用的问题。这里我们可以从系统的技术架构方面来探讨。系统的技术架构主要包括三个方面:前端、后端和数据库。在探讨保证系统高可用之前,我们要先探讨一下每一部分所面临的挑战。前端是所有用户的入口,它所面临的挑战是瞬间大流量;后端是对外提供服务的载体,它所面临的主要问题是用户大量请求所产生的高并发;而数据库是整个系统的基石,它所面临的主要挑战是后端发来的大量的读写请求。有了这个思路,我们就可以针对每一个挑战来提出解决方案。
前端高可用保证手段
前端是用户的入口,也是所有流量的入口,我们自然而然想到把集中的流量打散就可以解决问题,因此,前端的主要目标就是打散流量,主要有两种手段:一种是集群模式,这种方式很好理解,说白了就是简单的增加服务器,如果系统同时访问的用户请求峰值有 10 万,假如只有两台服务器,那每台服务器要承担的请求是 5w,如果把服务器增加到 10 台,同时配上负载均衡相关的组件,理论上,每台服务器就可以只承担 1 万请求,这就达到打散流量的目的了。另一种是动静分离,也就是说把动态资源和静态资源进行分离,用户直接从服务器上获取动态资源,而静态资源则放到 CDN 上,让用户从离自己最近的服务器上获取这些不变的数据资源,这也能达到打散流量的目的。
后端高可用的保证手段
后端是对外提供服务的载体,主要挑战是大量用户请求所产生的高并发和由高并发引起的服务雪崩等问题,因此后端高可用的主要目标是限制流量、提高响应速度和隔离风险。限制流量可以采用网景的 hystrix 或阿里的 Sentinel 等服务组件;提高响应速度,可以采用本地缓存与分布式缓存并存的方式;隔离风险,可以采取权限校验、服务隔离、业务隔离、中间件隔离、数据库隔离等方式。后端高可用是保证整个系统高可用的重点,所遇到的问题和所使用的技术都是层出不穷的。并且,后端保证高可用的具体操作方案还需要根据具体的业务规则及系统架构来分析,我们这里只提供一些通用的解决问题的思路,但是不管怎样,后端高可用的主要目标和保证高可用的手段是万变不离其宗的。
数据库的高可用保证手段
数据库是承载所有用户数据的地方,其地位不亚于后端服务系统,其所遇到的挑战除了高并发外,还有数据一致性问题的保证。针对高并发问题,我们可以在数据库侧采用分库分表、集群模式、读写分离的方式进行保证;针对数据一致性问题,我们需要根据具体的业务场景进行具体的分析,但如果后端使用了本地缓存与分布式缓存并存的方式,我们需要考虑这三方存储的数据一致性问题,一般是使用 CacheAside 模式。除此以外,还需要考虑前期系统设计方面的问题,即怎样设计出更能满足高可用目标的数据库表结构等。
其他高可用手段
除上述我们讲到的前端、后端及数据库三个方面的高可用保证手段外,还有为后端系统预热防止打死数据库,前后端开发保证高质量的代码,数据库保证高质量的 sql 脚本,测试阶段追求更高的测试覆盖率,运维为系统添加冗余以便出现问题后迅速切换、搭建完备的风险监控系统及日志监控系统都是保证系统高可用的手段。当然考虑这些时要根据企业的经济效益来考虑是否采用,这些保证手段也不是一下子全部都要用,而是在系统发展过程中不断完善的。
总结
整个视频合集,我们先是从系统不可用的背景进行切入,了解到系统不可用的根本原因是计算机应用的不断发展过程中遇到了各种各样的问题;其次我们从部署模型的视角,分析了系统有哪些不可用原因;再其次我们又提出了系统高可用的评判标准,最后我们又从技术架构的视角分析了系统高可用的保证手段。总而言之,如何设计一个高可用系统是一个复杂的问题,需要我们注意到应用系统的方方面面。当然上述视频中可能还会有其他暂时没有考虑到的问题,这就需要我们在业务迭代过程中不断进行发展和优化。此外,整个问题研究透彻之后,大家会发现计算机的发展之路其实就是不断发现问题并不断解决问题的道路,从另外一个角度来看,这也给我们学习计算机软件编程提供了思路。
**Service-Level Objective **(SLO): e.g. “99.9% of requests in a day get a response in 200 ms” **Service-Level Agreement **(SLA): contract specifying some SLO, penalties for violation
分布式系统的『三座大山』
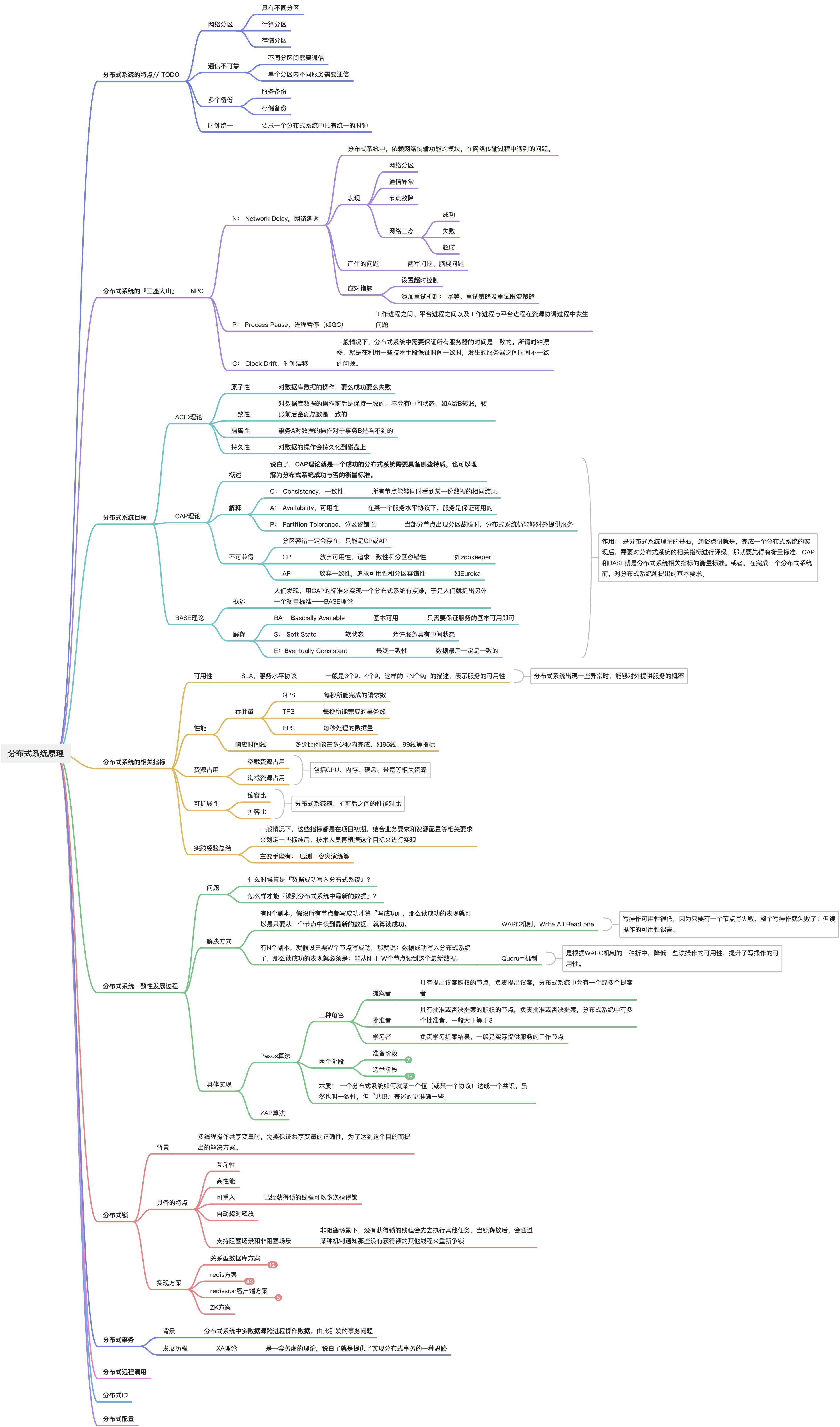
P90、P95、P99、P99.9 等